Symptom
You are interested in information about SAP HANA threads and thread samples.
Environment
SAP HANA
Cause
1. What are SAP HANA threads and thread samples?
2. Where do I find information about SAP HANA threads?
3. For what purpose do I need to evaluate the SAP HANA thread activities?
4. What kind of information is available for the SAP HANA threads?
5. How can I interpret the thread state?
6. What are the main thread types, methods and details?
7. How can I influence the collection and historization of thread samples?
8. What are typical thread constellations?
9. Are there case studies showing the possibilities of thread samples?
2. Where do I find information about SAP HANA threads?
3. For what purpose do I need to evaluate the SAP HANA thread activities?
4. What kind of information is available for the SAP HANA threads?
5. How can I interpret the thread state?
6. What are the main thread types, methods and details?
7. How can I influence the collection and historization of thread samples?
8. What are typical thread constellations?
9. Are there case studies showing the possibilities of thread samples?
Resolution
1. What are SAP HANA threads and thread samples?
The SAP HANA work, like executing of SQL statements or background tasks is performed by threads. Each SAP HANA process like indexserver or xsengine consist of a set of threads.Thread samples are regular samples of thread activities which are historized.
2. Where do I find information about SAP HANA threads?
Information about current SAP HANA threads can be found at the following locations:- Monitoring view M_SERVICE_THREADS
- SAP HANA Studio -> Administration -> Performance -> Threads
- DBACOCKPIT -> Performance -> Threads
- SQL: "HANA_Threads_CurrentThreads" (SAP Note 1969700)
- Monitoring view M_SERVICE_THREAD_SAMPLES
- Retention is usually at least 2 hours
- For more details see SAP Note 2088971
- History HOST_SERVICE_THREAD_SAMPLES
- Only available if embedded statistics server is used
- Default retention time may be quite small (1 day)
- Retention should be increased to 42 days as described in SAP Note 2147247 ("What is a good retention time for statistics server histories?")
- SQL: "HANA_Threads_ThreadSamples_FilterAndAggregation" (SAP Note 1969700)
- SQL: "HANA_Threads_ThreadSamples_AggregationPerTimeSlice" (SAP Note 1969700)
3. For what purpose do I need to evaluate the SAP HANA thread activities?
By checking SAP HANA thread information you can get a current or historic snapshot of thread activities. This can help you to answer questions related to the SAP HANA workload, e.g.:- Activities responsible for CPU consumption (SAP Note 2100040)
- Activities responsible for lock situations (SAP Note 1999998)
- Activities responsible for bad performance (SAP Note 2000000)
- Expensive SQL statements (SAP Note 2000002)
4. What kind of information is available for the SAP HANA threads?
The most important information available in the thread related monitoring views are:| Information | Column names | Available | Details |
| Host name Port Service name |
HOST PORT SERVICE_NAME |
generally | Basic information to understand which service on which host owns the thread |
| Timestamp | TIMESTAMP | M_SERVICE_THREAD_SAMPLES HOST_SERVICE_THREAD_SAMPLES |
Sample timestamp |
| Connection ID | CONNECTION_ID | generally | Client connection identifier (-1 if thread has no assigned client connection) |
| Thread ID | THREAD_ID | generally | Thread identifier |
| Statement hash | STATEMENT_HASH | M_SERVICE_THREAD_SAMPLES HOST_SERVICE_THREAD_SAMPLES |
Statement hash of active SQL statement |
| Active flag | IS_ACTIVE | M_SERVICE_THREADS |
TRUE if thread is currently active, otherwise FALSE History views only contain active threads, so flag is not required for M_SERVICE_THREAD_SAMPLES and HOST_SERVICE_THREAD_SAMPLES |
| Thread state | THREAD_STATE | generally | Activity state of thread (e.g. running or waiting for a resource), for more details see "What are the main thread types, methods and details?" below. |
| Thread type | THREAD_TYPE | generally | Thread type (e.g. SQLExecutor or JobWorker), for more details see "What are the main thread types, methods and details?" below. |
| Thread method | THREAD_METHOD | generally (but not consequently populated in thread sample views) |
Thread method (e.g. ExecutePrepared or indexing), for more details
see "What are the main thread types, methods and details?" below. Partially (e.g. for SqlExecutor threads) only written to thread sample views if the following parameter is set to true: global.ini -> [resource_tracking] -> service_thread_sampling_monitor_thread_detail_enabled = true |
| Thread detail | THREAD_DETAIL | generally (but not populated per default in thread sample views) |
Thread detail (e.g. SQL statement or column store plan step), for
more details see "What are the main thread types, methods and details?"
below Only written to thread sample views if the following parameter is set to true: global.ini -> [resource_tracking] -> service_thread_sampling_monitor_thread_detail_enabled = true |
| Caller thread Called thread |
CALLER CALLING |
M_SERVICE_THREADS M_SERVICE_THREAD_SAMPLES (>= SPS 09) |
Thread dependencies (caller: ID of thread which called the current thread; calling: ID of thread which is called by the current thread) |
| Database user name | USER_NAME | generally | Name of database user executing the thread |
| Application user name | APPLICATION_USER_NAME | generally | Name of application user (e.g. SAP end user in ABAP environments) |
| Application name | APPLICATION_NAME | M_SERVICE_THREAD_SAMPLES HOST_SERVICE_THREAD_SAMPLES |
Name of client application (e.g. "ABAP:<sid>" in case of SAP ABAP stacks) |
| Application source | APPLICATION_SOURCE | M_SERVICE_THREAD_SAMPLES HOST_SERVICE_THREAD_SAMPLES |
Application details (e.g. report name in case of SAP ABAP stacks) |
| CPU time | CPU_TIME_SELF CPU_TIME_CUMULATIVE |
M_SERVICE_THREADS |
CPU time in microseconds consumed by the thread itself
(CPU_TIME_SELF) or including the associated children
(CPU_TIME_CUMULATIVE) Only populated if the following SAP HANA parameter is set: global.ini -> [resource_tracking] -> cpu_time_measurement_mode = fast (SPS 08 and below) global.ini -> [resource_tracking] -> cpu_time_measurement_mode = on (SPS 09 and above) |
| Transaction ID Update transaction ID |
TRANSACTION_ID UPDATE_TRANSACTION_ID |
generally | Identifier of related transaction (-1 if no transaction is associated to thread) and update transaction (-1 if no uncommitted modification is associated to thread) |
| Lock wait details | LOCK_WAIT_COMPONENT LOCK_WAIT_NAME LOCK_OWNER_THREAD_ID |
generally | Component, details of lock waits and ID of thread being responsible for lock wait |
5. How can I interpret the thread state?
Thread states are useful to judge if the threads are actually working or if they have to wait, so they are one aspect of a general performance analysis (SAP Note 2000000):| Thread state | Area | Details | SAP Note |
| Barrier Wait | Lock | Barrier wait | 1999998 |
| ConditionalVariable Wait | Lock | Mainly record and table lock waits | 1999998 |
| ExclusiveLock Enter | Lock | Exclusive read / write lock waits | 1999998 |
| Inactive | Idle | Idle thread | |
| IO Wait | I/O | Disk I/O wait (e.g. during column load or hybrid LOB access | 1999930 |
| Job Exec Waiting | Idle | Waiting for a JobWorker thread executing the actual work | |
| Mutex Wait | Lock | Mutex lock waits | 1999998 |
| Network Poll | Network | Network I/O between SAP HANA nodes or services | 2222200 |
| Network Read | Network | Network I/O read between SAP HANA nodes or services | 2222200 |
| Network Write | Network | Network I/O write between SAP HANA nodes or services | 2222200 |
| Running | SQL | Request execution, typically CPU consumption | 2000002 |
| Semaphore Wait | Lock | Semaphore lock waits | 1999998 |
| SharedLock Enter | Lock | Shared read / write lock waits | 1999998 |
| Sleeping | Lock | Waiting for a lock | 1999998 |
6. What are the main thread types, methods and details?
Below you can find some important thread types, methods and details:| Thread Type | Thread Method | Thread Detail | SAP Note | Tasks |
| Assign | assign | open data+log volume <id> / local tables | 2185955 |
Indexserver -> nameserver communication in order to open disk volumes May be blocked if nameserver has issues, e.g. due to an orphan nameserver process like described in SAP Note 2185955 |
| post_assign | open data+log volume <id> / preload tables | 2127458 |
Reloading tables at the end of startup and volume assignment |
|
| AsyncSender | send | working for thread <waiting_thread> | Asynchronous thread / thread communication (sending thread) | |
| AsyncWaiter | waiting | working for thread <sending_thread> | Asynchronous thread / thread communication (waiting thread) | |
| BWFlattenScenarioHost | BWFlattenScenarioHost | <host>:<port> partGroup 0 | Conversion of BW infocubes from classic to in-memory (BW_CONVERT_CLASSIC_TO_IMO_CUBE) | |
| Cache Request Handler | ||||
| CatalogWatchdog | ||||
| DiskInfo | remotediskinfo | Request of information for remote physical disk | ||
| DsoUpdate | ActivationQueuePackage | <schema>:<table>en: [<id>, <id>) / {Lhs table parts: [<schema>:<table> (<id>)] (not prunable: size 1 set 0), rhs table parts: [<schema>:<table> (<id>)]} | 2000002 | DSO activation via DSO_ACTIVATE_PERSISTED |
| DSOPartActivatorLocal | <schema>:<table>en RequestIds <id> / {Lhs table parts: [<schema>:<table> (<id>)] (not prunable: size 1 set 0), rhs table parts: [<schema>:<table> (<id>)]} | 2000002 | DSO activation via DSO_ACTIVATE_PERSISTED | |
| EmergencyJobForDeferredResource |
2127458 |
Framework used during critical situations (e.g. for unloading columns during memory shortages) |
||
| Generic | 1999880 |
A running 'Generic' thread without further method or detail information and with DataAccess::AsyncLogBufferHandlerThread::run in its call stack is responsible for shipping log buffers in asynchronous system replication environments. |
||
| Generic | Search for trace files to compress | 2119087 |
Check if trace files (e.g. alert traces) exist that should be compressed Peaks can be caused by I/O issues accessing the trace files (see SAP Note 1999930), example for an I/O related call stack: __open_nocancel+0x7 __opendir+0x1 System::UX::opendir FileAccess::DirectoryEntry::findFirst FileAccess::DirectoryEntry::DirectoryEntry Diagnose::TraceSegmentCompressorThread::run __getdents+0x6 __readdir_r+0x105 System::UX::readdir_r FileAccess::DirectoryEntry::findFirst FileAccess::DirectoryEntry::DirectoryEntry Diagnose::TraceSegmentCompressorThread::run |
|
| getLastDocids | byValue | $trexexternalkey$ from=<id> to=<id> | ||
| IndexingQueue | indexing | <schema>:<table>en.<column> | 2160391 | Indexing of fulltext indexes |
| JobexWatchdog | Watchdog for job execution | |||
| JobWorker | aggregate | worker <schema>:<table>en(<pct>%) | ||
| AttributeIndexJob | commitOptimize worker (table oid: <id>, attribute <column>) writing <num> rows | |||
| Backup::BackupExe_Job | 1642148 | Threads actually performing the backup, often triggered by _IDX_BackupExecutor slaves | ||
| BackupMgr_ExecuteDataSaveJob | 1642148 | Data backup threads typically triggered by BackupMgr_SaveDataJob | ||
| BackupMgr_SaveDataJob | 1642148 | Main data backup thread | ||
| calculateQueryResultDocs2 | resultdocs | Parallelized query result processing in column store | ||
| CeCalcAttrMaterializeJob | ||||
| changeCompression ChangeCompressionJob |
ChangeCompressionJob: table=<schema>:_SYS_SPLIT_<table>~<id> (<id>), columnId=<id>: changeAttributeDefinition table=<schema>:<table> (<id>), columnId=<id>: getEstimatedTotalMainMemSize |
2112604 | Compression optimization (adjustment of column compression) | |
| changeRowOrder | PrepareRenumberJob: table=<schema>:_SYS_SPLIT_<table>~<id> (<id>), columnId=<id>: prepareRenumber | 2112604 | Compression optimization | |
| CHECK_TABLE_CONSISTENCY/local |
checking row table <schema>.<table> checking column table <schema>.<table> |
1977584 | Execution of consistency check CHECK_TABLE_CONSISTENCY | |
| comm | ||||
| CompressFemsParallel | 1999997 |
FEMS compression See SAP Note 1999997 -> "What can I do if a certain heap allocator is unusually large?" -> "Pool/FemsCompression/CompositeFemsCompression" for more information. |
||
| createJobs | RadixSort | |||
| create_ReadValueId_Jobs | GetValueIds | |||
| createResultDocs | Creation of results of parallel OLAP engine activities | |||
| DDLDataJob | <schema>:_SYS_SPLIT_<table_name>~<id> (<id>) | |||
| DefaultColumnDict | ||||
| detachResult | merger <id> | |||
| DictScanJob | ||||
| estimateCompression | EstimateCompressionJob: table=<schema>:_SYS_SPLIT_<table>~<id> (<id>), columnId=<id>: chooseCompression | Compression optimization (identification of optimal compression) | ||
| EXPORT thread | Table-wise EXPORT thread for <schema>:<table> | Table export | ||
| FemsCompressionPhase2Job | Phase <id> Job <id> Num of parts: <id> | |||
| GCJob@<identifier> | GCJob[<identifier>-EID, CleanupFilePassedToGC, TID= <sid>, transIndex= <id>, CleanupStrategy_MVCC, pagecnt=<pg>, size=<size> | 2169283 | Persistence garbage collection | |
| generic | BuildIndexJobNode | |||
| commitOptimize worker (table oid: <id>, attribute <column>) writing 1800 rows | Can be linked to mass changes (e.g. UPSERT) | |||
| ConcatenateAttributesJob | ||||
| RowInsertJobNode | ||||
| EmailJob: working on snapshot_ID: <date> | 1999998 | E-mail processing, may be blocked by MailSenderCallback semaphore waits, see SAP Note 1999998 for more details. | ||
| getMostFrequentValueInfos | GetMostFrequentValueInfosJob: table=<schema>:_SYS_SPLIT_<table>~<id>(<id>), column=<id> | 2112604 | Compression optimization | |
| getNextPQItem | UpdateMostFrequentValueCountJob | |||
| GroupBy-group | Row store GROUP BY / DISTINCT processing | |||
| _handleQuery | ||||
| HashDict WorkerJob | HashDict worker <num>% done | |||
| HashDict MergerJob | HashDict merger <id> | |||
| HTTP | POST <connector> PUT <connector> |
HTTP request processing (xsengine) | ||
| IndexConsistencyCheckData | 1977584 | Consistency check based on CHECK_TABLE_CONSISTENCY | ||
| IndirectScanBvOutJob<range> IndirectScanVecOutJob<range> |
2000002 |
Range scan of column with INDIRECT compression |
||
| initIteratorMultiBtQuery | initIteratorMultiBtQuery | |
||
| JobConcatAttrCalculator | JobConcatAttrCalculator<schema>:<table>en <rows> rows | 1986747 | Creation of a CONCAT attribute, e.g. during index creation | |
| JobReadValueIdsParallel | ||||
| makeHeap | MakeHeapJob | |||
| OrderBy-fetch | Row store ORDER BY processing | |||
| execute ParallelForJob ParallelFor Job |
AE/getValues BlockJob on table <schema>:<table> (<id>) (parallelFor job <id>/<id>) AE/getValues SliceJob on table <schema>:_SYS_SPLIT_<table> (<id>) (parallelFor job <id>/<id>) |
|||
| calc PlanExecutor calc |
plan<id>@<host>:<port>/pop<id> (<action>) | 2000002 | Column store plan execution | |
| PlanExecutor comm | ||||
| postProcessScanVecResult | SetRangeVecOutJob | 2112604 | Compression optimization | |
| processParallel | ||||
| readIndexChunked | readIndexChunked | |||
| RSVersionCollectorJobNode/Partition<part> | remaining versions to collect: <versions> versions (<tx> tx, <flushes> flushes) | 2169283 | These threads are triggered by the MVCCGarbageCollector garbage collector thread in order to perform parallelized row store version consolidation. | |
| runJobs | ItabMat-insert | |||
| scanParallel | ||||
| scanWithoutIndex | IndScanVecOutJob | |||
| IndScanBvOutJob | ||||
| searchBetween | searchBetween | |||
| searchDocumentsIterateDocidsParallel | JobParallelMgetSearch docs=<val1>(VEC) vid=<val2>(BV) | 2000002 | Table scan | |
| ServerJob | Unnamed-SimpleJob | 2222218 | Execution of hdbcons command (caller: NetworkChannelCompletionThread) | |
| SetAttributeJob | Source attribute: <column> dest attribute: <column> | Conversion of BW infocubes from classic to in-memory (BW_CONVERT_CLASSIC_TO_IMO_CUBE) | ||
| SidMappingJob | SidMappingJob: source scenario <schema>:<scenario> , mapping to new attribute <column> (<id> values) | Conversion of BW infocubes from classic to in-memory (BW_CONVERT_CLASSIC_TO_IMO_CUBE) | ||
| Sorter | RangeSortJob | |||
| sortBlocksByRowID | SortByRowIdJob: table=<schema>:_SYS_SPLIT_<table>~<id> (<id>) | 2112604 | Compression optimization | |
| sortRestRanges | SortRestRangeJob: table=<schema>:_SYS_SPLIT_/<table> (<id>), columnId=<id> | 2112604 | Compression optimization | |
| sparseSearch | SparseScanRangeVecJob | 2000002 | Scan of column with SPARSE compression | |
| spSearchValueCountsFastScan | Ad-hoc attribute engine scan for counting values (e.g. when RECORD_COUNT is selected from M_CS_COLUMNS / M_CS_ALL_COLUMNS) | |||
| startLoop | ||||
| system replication: async log buffer handler | Unnamed-JobNode | 1999880 | Handler thread, that picks log buffers from the temporary memory buffer and sends them over the network to the secondary site. If asynchronous replication is enabled, this thread is running always (maybe waiting for new log buffers to be created). | |
| system replication: mark shipped snapshot active | Unnamed-JobNode | 1999880 | After a successful data shipping, the snapshot that has been used as source on primary site is marked as active snapshot (last shipped snapshot to secondary site). | |
| system replication: prepare transfer data replica to secondary | Unnamed-JobNode | 1999880 | Preparation of a new data shipping from primary to secondary site, snapshot for data shipping is created on primary site, that is used as source for data transfer. | |
| system replication: check replication snapshots | Unnamed-JobNode | 1999880 | Check whether old replication snapshots can be dropped on primary site, snapshots are dropped if they are no longer needed or the snapshot's retention time has been elapsed. | |
| system replication: transfer missing log to secondary | Unnamed-JobNode | 1999880 | Transfer of missing log to the secondary site, that is required to make the backup history complete. | |
| system replication: transfer replica to secondary | Unnamed-JobNode | 1999880 | Execution of data shipping from primary to secondary site. | |
| WorkerJob | worker <schema>:_SYS_SPLIT_<table>~<id>en (merging) | Merging of parallel OLAP engine data sets | ||
| writeDataIntoDelta | Creating concat for <schema>:_SYS_SPLIT_<index>$history$$delta_1$en | 2057046 | Writing of delta storage information | |
| Zipper | ||||
| LoadDataWriter | 2222110 |
Responsible for writing the SAP HANA load history May be impacted by I/O problems related to trace file directory (SAP Note 1999930), example call stacks: __open_nocancel+0x20 __GI__IO_file_open+0x30 _IO_new_file_fopen+0xc7 __fopen_internal+0x80 NameServer::LoadHistoryManager::save NameServer::LoadDataWriter::ru __close_nocancel+0x7 _IO_new_file_close_it+0x40 _IO_new_fclose+0x180 NameServer::LoadHistoryManager::save NameServer::LoadDataWriter::run |
||
| LoadField | <schema>:<table>en | AttributeId=<id> <column> |
2127458 | Load of columns into column store |
| LoadPart | load | <schema>:_SYS_SPLIT_<table>~<id>en | 2127458 | Load of columns of partitioned table into column store |
| LobGarbageCollector | 2169283 | Lob persistence garbage collection | ||
| LocalWatchDog | ping | <host>:<port> | Nameserver ping check of indexserver | |
| LogBackupThread | ||||
| Main | ||||
| MemoryCompactor | 2169283 | Memory garbage collection | ||
| MergeAttributeThread | prepareDeltaMerge | IndexName: <schema>:<table>en Attribute: <id>/<column> | 2057046 | Preparation of delta merges |
| MergedogMerger | merging | <x> of <y> table(s): <table> | 2057046 | Execution of delta merges |
| MergedogMonitor | joining | waiting for merge threads to complete | 2057046 | Delta merge monitoring (waiting for merge threads) |
| checking | <x> of <y> table(s): <schema>:_SYS_SPLIT_<table>~<id> | 2057046 | Delta merge monitoring (checking) | |
| MvccAntiAgerChecker | 2169283 | Row store version consolidation and garbage collection check | ||
| MVCCGarbageCollector | 2169283 | Row store version consolidation and garbage collection | ||
| PartDistributorThread | PartDistributorThread | 2044468 | Access and modification of records into appropriate table partition | |
| PeriodicSavepoint | doSavepoint | enterCriticalPhase | 2100009 | Preparations for entering the critical savepoint phase (part of CRITICAL_PHASE_WAIT_TIME in M_SAVEPOINTS, change operations like DML, DDL or merges can be blocked with ConsistentChangeLock, see SAP Note 1999998) |
|
enterCriticalPhase(waitForLock) |
2100009 | Preparations for entering the critical savepoint phase (part of CRITICAL_PHASE_WAIT_TIME in M_SAVEPOINTS, change operations like DML, DDL or merges can be blocked with ConsistentChangeLock, see SAP Note 1999998) | ||
| enterPostCriticalPhase | 2100009 | Savepoint processing after critical phase | ||
| exitCriticalPhase | 2100009 | End of critical savepoint phase | ||
| finishSavepoint | 2100009 | Final savepoint steps | ||
| flushPagesinNonCriticalPhase | 2100009 | Savepoints writing dirty pages to disk | ||
| preCriticalPhase | 2100009 | Savepoint activity before starting critical phase | ||
| prepareSavepoint | 2100009 | Savepoint preparation | ||
| processCriticalPhase | 2100009 | Critical savepoint phase (CRITICAL_PHASE_DURATION in M_SAVEPOINTS, change operations like DML, DDL or merges can be blocked with ConsistentChangeLock, see SAP Note 1999998) | ||
| PhraseIndexBuilder | update_phrases | <schema>:<table>en.<column> | 2160391 | Maintenance of fulltext indexes |
| Queue | indexing | <schema>:<table>en.<column> | 2160391 | Indexing of fulltext indexes |
| RemoteService | ||||
| Request | BackupManager | |||
| bwFlattenScenarioPart | Conversion of BW infocubes from classic to in-memory (BW_CONVERT_CLASSIC_TO_IMO_CUBE) | |||
| cachemgr | ||||
| CheckRemoteUniqueConstraint | 2044468 |
Check of uniqueness in other partitions / hosts, should be avoided if possible (e.g. by avoiding partitioning or by performing partitioning based on unique / primary key columns) Avoid partitioning of SID tables in BW, because they typically have two different unique indexes. For data management of SID tables see SAP Note 1331403. |
||
| csddl/TruncateTableData | ||||
| remotediskinfo | Collection of information for local physical disk by nameserver (NameServer::doRemoteDiskInfo) in order to support a remote request | |||
| distMetdataRequest | Distributed metadata request | |||
| DistRowQueryExecute | ||||
| DistTableStatistics | ||||
| dso/activatePers | 2000002 | DSO activation via DSO_ACTIVATE_PERSISTED | ||
| executeTableUpdateContainer | ||||
| fs | ||||
| getColumnStat | Determination of column statistics | |||
| __globalTransControl | Control of global transactions involving different services | |||
| _IDX_BackupExecutor | 1642148 | Backup executor threads, typically triggered by BackupMgr_ExecuteDataSaveJob slaves | ||
| __nsWatchdog | Triggered by nameserver watchdog (LocalWatchDog) | |||
| LOBREMOTE | <schema>:<table>en/getContainerIdsFromTable | 2220627 | LOB container access | |
| memoryutilization | ||||
| ngdb_console | runtimedump dump | 1813020 | Creation of a runtime dump using MANAGEMENT_CONSOLE_PROC / hdbcons | |
| OptimizeCompressionData | 2112604 | Compression optimization (triggering JobWorker processes doing the actual work) | ||
| planexecution | X2 plan execution | |||
| prep/indexing | TEXT/<schema>:<table>en.<column>:<id> | 2160391 | Indexing of fulltext indexes by preprocessor | |
| Queue Master | ||||
| Queue Pull | Preprocessor request to indexserver for job workers that can be used for preprocessor activities like 'indexing' | |||
| reclaim_data_volume | Execution of 'ALTER SYSTEM RECLAIM DATAVOLUME' command | |||
| RemotePersistenceNoSession | ||||
| search | <schema>:<table>/<conditions> | |||
| __sessionRequest | ||||
| splitIndex | <schema>:<table> | Repartitioning of tables, triggers threads like (e.g type 'Split', method 'split/merge attributes') | ||
| stat core/stat |
||||
| SaveMergedAttributeThread | prepareDeltaMergeSave | IndexName: <schema>:<table>en Attribute: <id>/<column> | 2057046 | Preparation of perstisting delta merge to disk |
| Savepoint | Savepoint execution | |||
| SelfWatchDog | 1999998 |
Watchdog thread that regularly checks for the existence of the nameserver topology lock file An increased amount of SelfWatchDog activities can indicate issues accessing the lock file. See SAP Note 1999998 for more details. |
||
| service thread sampler | interval 1 sec. | 2114710 | Collection of M_SERVICE_THREAD_SAMPLES information (1 second sampling interval) | |
| SignalQueue | ||||
| SmartMerger | waiting | <schema>:_SYS_SPLIT_<table>~1en | 2057046 | Execution of smart merges |
| Split | split/merge attribute | <schema>:<table> <column> | Processing of column during table repartitioning, triggered by threads with type 'Split' and method 'splitIndex' | |
| SqlExecutor | Authentication | Password check and update of access information like "last login time" in SAP HANA tables | ||
| BatchExecute | (batch size:<size>) <sql_statement> | 2000002 | Execution of a batch SQL statement (e.g. bulk INSERT inserting multiple rows) | |
| CloseStatement | 2000002 | Closing of a SQL statement | ||
| CollectVersion | Row store version collection | |||
| CommitTrans | 2000000 | Execution of a COMMIT | ||
| CursorFetchItab | 2000002 | |||
| ExecQidItab | 2000002 | |||
| ExecutePrepared | <sql_statement> | 2000002 | Execution of a prepared SQL statement (using bind variables) | |
| ExecuteStatement | <sql_statement> | 2000002 | Execution of a SQL statement | |
| FetchCursor | <sql_statement> | 2000002 | Execution of a SQL statement | |
| LobPutPiece | 2220627 | |||
| PrepareStatement | <sql_statement> | 2000002 | Preparation of a SQL statement | |
| SystemReplicationIniFileWatchDog | 1999880 | Responsible for detecting differences in configuration parameter settings between primary and secondary site | ||
| TableReload | reloading table | <schema>:<table>en | 2127458 | Reload of table columns into memory by triggering LoadField threads |
| WorkerThread (StatisticsServer) | running ID (<id>, deletion: no) for <date> | 1917938 | Activity of embedded statistics server | |
| XS | Execution of XS engine requests |
7. How can I influence the collection and historization of thread samples?
In general it is not required to manually adjust the collection and historization of thread samples. In specific scenarios you can adjust the following settings based on your needs:| Parameter | Details |
global.ini -> [resource_tracking] -> cpu_time_measurement_mode |
Controls the collection of CPU time information in (CPU_TIME_SELF, CPU_TIME_CUMULATIVE):
|
global.ini -> [resource_tracking] -> service_thread_sampling_monitor_enabled |
Controls the collection of thread samples in M_SERVICE_THREAD_SAMPLES:
|
global.ini -> [resource_tracking] -> service_thread_sampling_monitor_max_sample_lifetime global.ini -> [resource_tracking] -> service_thread_sampling_monitor_max_samples |
Control the availability of data in M_SERVICE_THREAD_SAMPLES. See SAP Note 2088971 for more information. |
global.ini -> [resource_tracking] -> service_thread_sampling_monitor_sample_interval |
Controls the frequency of thread sample times in M_SERVICE_THREAD_SAMPLES in seconds. The value must be between 1 (default) and 100. |
global.ini -> [resource_tracking] -> service_thread_sampling_monitor_thread_detail_enabled |
Controls the recording of THREAD_DETAIL information in M_SERVICE_THREAD_SAMPLES:
|
8. What are typical thread constellations?
There are often caller / calling dependencies between a set of threads. Below you can find typical examples.Example 1: "Complex" column store SQL statement execution
A SQL statement is in the first place executed by a SqlExecutor thread, but this thread may delegate work to JobWorker threads and also JobWorkers may call additional JobWorkers. In this example we can see a hierarchy of four levels. the main SqlExecutor thread 151759 calls the JobWorker thread 111596, this thread calls JobWorker thread 92120 and this thread calls the four JobWorker threads 37304, 111416, 111437 and 111609. Only the four last threads are active at the sample time ("Running") while the other threads are in status "Job Exec Waiting":

Example 2: Delta merge
Delta merges are performed by various merge related threads supervised by the MergedogMonitor. In the following case the MergeAttributeThreads are active ("Running") processing columns MANDANT and $trexexternalkey$ of table BALDAT while the other involved processes have to wait for them to finish. When they are finished, the SaveMergedAttributeThread will take over and finish the merge.

Example 3: Nameserver ping
The namesever regularly executes ping operations to the index server ("Index Server" -> "Ping Time" in Load Graph). This happens with the following intra-node process communication. The first line is the nameserver thread having sent the "ping" request to the indexserver thread in the second line:

Example 4: Column load
When a query requires data from a column that isn't loaded into memory, yet, it has to wait for the related column load ("AttributeStore Resource Load"). The following table shows an example where queries have to wait until column DATA of table SWWCNTP0 is loaded:

9. Are there case studies showing the possibilities of thread samples?
Analyzing thread samples is an integral part of SAP HANA performance analysis. In the following some real-life cases are discussed.Case study 1: Long-running INSERT due to critical savepoint phases
A simple INSERT of one record had a high average execution time of 10 ms without any apparent issue visible in the SQL cache. We analyzed the thread samples for the related statement hash on a granular time slice basis of 1 second in terms of THREAD_STATE and the result showed time frames of around 8 seconds where multiple concurrent INSERTs waited for "SharedLock Enter" (see below). Based on SAP Note 1999998 this can be caused by blocking situations due to the critical savepoint phase. A check based on M_SAVEPOINTS in deed showed repeated critical savepoint phases of 8 seconds and more. The customer double-checked the I/O performance (SAP Note 1999930) and was able to improve it with technical changes. Afterwards the INSERT times significantly improved.

Case study 2: High system CPU consumption due to garbage collectors
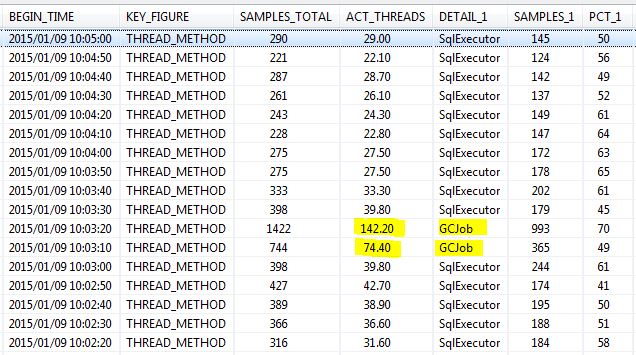
Spikes of system CPU consumption were observed, e.g. between 10:03 and 10:04. SQL: "HANA_Threads_ThreadSamples_AggregationPerTimeSlice" (AGGREGATE_BY = 'THREAD_METHOD', TIME_SLICE_S = 10) reported a high number of concurrent garbage collectors ('GCJob') as seen below, so we can conclude that they are responsible for the increased CPU consumption. If these kinds of CPU spikes are critical for the system, the parallelism of the garbage collectors could be reduced using the max_gc_parallelity parameter (see SAP Note 2100040).
Case study 3: High user CPU consumption caused by specific application users
The system suffered from massive CPU peaks during certain time frames. Using SQL: "HANA_Threads_ThreadSamples_AggregationPerTimeSlice" (AGGREGATE_BY = 'APP_USER', TIME_SLICE_S = 60) we were able to identify application users being responsible for a high load (see below). In the next step the activity of these users was analyzed by checking related batch jobs and asking the users for their online operations and technical optimizations were implemented.

Case study 4: Top SQL statements responsible for load in a specific time frame
A popular evaluation of thread samples is the determination of SQL statements responsible for the highest SAP HANA load (see SAP Note 2000002). This can be done via SQL: "HANA_Threads_ThreadSamples_FilterAndAggregation" (AGGREGATE_BY = 'STATEMENT_HASH'). In the example below we can see the top SQL statements like statement hash 696d5f902df56c3228a80bd25ef71ee3 that can subsequently be analyzed and tuned as described in SAP Note 2000002. Thread samples without a specific statement hash are reported with "no SQL" and the thread method or thread type is added in brackets. "no SQL (SqlExecutor)" can be linked to thread methods like "execQidItab" or "CommitTrans" which don't have a SQL statement assigned.

Case study 5: High system load due to table scans
During times of very high system load a lot of threads with THREAD_METHOD 'searchDocumentsIterateDocidsParallel' were observed in M_SERVICE_THREADS (see below). This method indicates table scans and usually points to a missing index. Further analysis revealed that one central, frequently executed SQL statement wasn't supported by an index. After having created an appropriate index, the maximum CPU consumption went down from 100 % to 10 %.

Header Data
| Released On | 01.02.2016 11:27:23 |
| Release Status | Released to Customer |
| Component | HAN-DB SAP HANA Database |
| Priority | Normal |
| Category | How To |
I really appreciate information shared above. It’s of great help. If someone want to learn Online (Virtual) instructor led live training in SAP HANA , kindly Contact GRONYSA
ReplyDeleteClick for SAP HANA Course details SAP HANA
GRONYSA Offer World Class Virtual Instructor led training on SAP HANA. We have industry expert trainer. We provide Training Material and Software Support. GRONYSA has successfully conducted 10,000 + trainings in India, USA, UK, Australlia, Switzerland, Qatar, Saudi Arabia, Bangladesh, Bahrain and UAE etc.
For Demo Contact us.
Nitesh Kumar
GRONYSA
E-mail: nitesh.kumar@gronysa.com
Ph: +91-9632072659/ +1-2142700660
www.GRONYSA.com
Hi There,
ReplyDeleteThank you for update. From now onward I start to use this blog in my training practice. Thank you for explaining in each step. I use blogs for my easy reference which were quite useful to get started with.
We have a CAL System for Hybrid Marketing. The replication of business partner data between sap CRM and hybrids marketing failed.
We get the following error in transaction LTRO: CNV_DMC_HC 019
Trying to check the db-connection 010: R: R (Report ADBC_TEST_CONNECTION) error "sql error 10 occurred: authentication failed" occurred.
It enables technical users to manage the SAP HANA database, to create and manage user authorizations, to create new, or modify existing models of data etc.,
Also, a connect to HANA DB with SYSTEM USER is not possible.
Anyways great write up, your efforts are much appreciated.
Many Thanks,
Kapoor
Hello There,
ReplyDeleteThank You so much for this blog. It helped me lot. I am a Technical Recruiter by profession and first time working on this technology was bit tough for me, this article really helped me a lot to understand the details to get started with.
I heard a buzzword "Optimistic Latch-Free Index Traversal" in one blog post on Introduction to SAP HANA by Dr. Vishal Sikka. I googled about it in context of SAP HANA Architecture but didn't find anything concrete. Could someone please explain this whole concept thoroughly, in context of SAP HANA?
By the way do you have any YouTube videos, would love to watch it. I would like to connect you on LinkedIn, great to have experts like you in my connection (In case, if you don’t have any issues).
Please keep providing such valuable information.
Best Regards,
Stephen
Greetings Mate,
ReplyDeleteThat’s really cool…. I followed these instructions and it was like boom… it worked well..
This is from my understanding.
You have the UiRobotSvc service that runs on the machine and that’s how the Robot is able to run. Once the job starts, it opens the UiRobot.exe process until the job is finished. If you are running SAP HANA tutorial USA this job unattended through Orchestrator it runs the job the same and only if the UiRobotSvc is running on the machine. The user id for the Robot will need Remote access or Admin authorization on the machine in order to run the job unattended.
Appreciate your effort for making such useful blogs and helping the community.
Many Thanks,
Abhiram